La adopción de Inteligencia Artificial en aplicaciones de escritorio ha evolucionado rápidamente en los últimos años. Sin embargo, una de las decisiones más críticas —y menos comprendidas— es elegir entre ejecutar modelos de IA localmente o consumir servicios en la nube.
Esta decisión no es técnica únicamente, es arquitectónica. Impacta directamente en la experiencia de usuario, costos operativos, seguridad, latencia, escalabilidad y mantenibilidad del sistema.
Este artículo presenta un análisis profundo y práctico de ambas estrategias (IA local vs IA en la nube), incluyendo patrones reales, decisiones arquitectónicas, trade-offs y escenarios híbridos utilizados en aplicaciones modernas.
Existen dos enfoques principales para integrar IA en aplicaciones de escritorio:
- IA en la nube (Azure OpenAI, APIs externas)
- IA local (modelos ejecutándose en el dispositivo)
Y un tercer enfoque emergente:
- Arquitecturas híbridas (lo mejor de ambos mundos)
Cada uno tiene ventajas y limitaciones que deben evaluarse cuidadosamente.
El problema real Link to heading
Errores comunes:
- Elegir cloud sin considerar costos
- Elegir local sin considerar hardware
- No manejar latencia
- No diseñar fallback
- No considerar privacidad
Ejemplo típico Link to heading
Aplicación usa solo cloud:
var result = await _ai.ProcessAsync(input);
Problemas:
- falla sin internet
- latencia alta
- dependencia externa
IA en la nube Link to heading
Qué es Link to heading
Uso de servicios como:
- Azure OpenAI
- Azure AI Services
- APIs externas
Ventajas Link to heading
1. Potencia Link to heading
- modelos grandes
- mayor precisión
- capacidades avanzadas
2. Escalabilidad Link to heading
- no depende del cliente
- backend maneja carga
3. Actualización constante Link to heading
- modelos mejoran sin intervención
4. Simplicidad inicial Link to heading
- integración rápida
Desventajas Link to heading
1. Latencia Link to heading
await Task.Delay(500);
Esto impacta UX.
2. Dependencia de red Link to heading
- offline imposible
3. Costos Link to heading
- pago por uso
- tokens
4. Privacidad Link to heading
- datos enviados a la nube
IA local Link to heading
Qué es Link to heading
Ejecutar modelos directamente en el dispositivo:
- ONNX
- modelos cuantizados
- LLMs locales
Ventajas Link to heading
1. Latencia mínima Link to heading
var result = localModel.Run(input);
Respuesta inmediata.
2. Offline Link to heading
- funciona sin internet
3. Privacidad Link to heading
- datos no salen del dispositivo
4. Costos Link to heading
- sin costo por request
Desventajas Link to heading
1. Limitaciones de hardware Link to heading
- CPU/GPU
- memoria
2. Tamaño de modelos Link to heading
- distribución compleja
3. Actualización Link to heading
- requiere despliegue
4. Calidad Link to heading
- modelos más pequeños
Comparación directa Link to heading
| Aspecto | Cloud | Local |
|---|---|---|
| Latencia | Alta | Baja |
| Offline | No | Sí |
| Costos | Variables | Fijos |
| Privacidad | Menor | Alta |
| Potencia | Alta | Limitada |
Arquitectura cloud típica Link to heading
WinUI → Backend → Azure AI
Arquitectura local Link to heading
WinUI → Local AI Engine
Arquitectura híbrida (recomendada) Link to heading
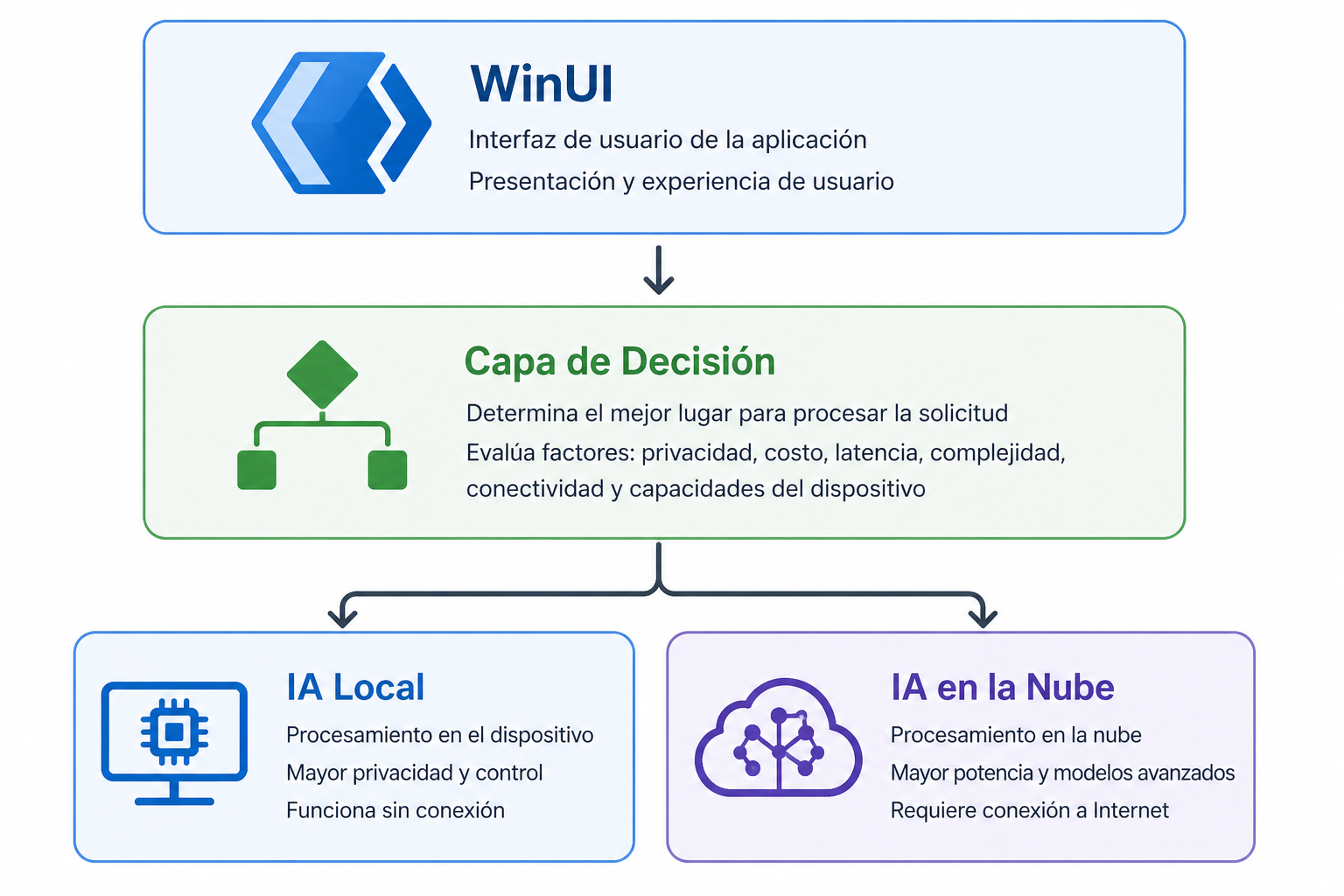
Paso 1: Decision Engine Link to heading
public class AIOrchestrator
{
public async Task<string> Process(string input)
{
if(IsOffline())
return await _local.Process(input);
return await _cloud.Process(input);
}
}
Paso 2: Fallback automático Link to heading
try
{
return await _cloud.Process(input);
}
catch
{
return await _local.Process(input);
}
Paso 3: Clasificación de tareas Link to heading
No todas las tareas requieren cloud.
Ejemplo:
- clasificación simple → local
- generación compleja → cloud
Paso 4: Cache inteligente Link to heading
if(cache.Exists(input))
return cache.Get(input);
Reduce llamadas cloud.
Paso 5: Seguridad Link to heading
Cloud:
- usar backend
- proteger claves
Local:
- proteger modelo
- evitar ingeniería inversa
Paso 6: UX Link to heading
Mostrar:
- modo offline
- modo cloud
Paso 7: Performance Link to heading
Local:
- optimizar modelo
- usar GPU
Cloud:
- minimizar llamadas
- usar batching
Paso 8: Costos Link to heading
Cloud:
- controlar tokens
- limitar uso
Local:
- costo inicial
Paso 9: Escenarios reales Link to heading
Escenario 1: Editor de texto Link to heading
- sugerencias → local
- generación avanzada → cloud
Escenario 2: App empresarial Link to heading
- datos sensibles → local
- análisis complejo → cloud
Escenario 3: App offline Link to heading
- todo local
Paso 10: Problemas reales Link to heading
- inconsistencia entre modelos
- resultados diferentes
- sincronización
Paso 11: Estrategia profesional Link to heading
Una arquitectura madura incluye:
- orquestación
- fallback
- observabilidad
- optimización de costos
Buenas prácticas Link to heading
- no elegir solo una estrategia
- diseñar híbrido
- medir performance
- controlar costos
- priorizar UX
Conclusión Link to heading
La elección entre IA local y cloud no es binaria. Las aplicaciones modernas deben diseñarse para aprovechar ambas estrategias de forma inteligente.
El enfoque híbrido es el que permite construir aplicaciones robustas, eficientes y alineadas con escenarios reales.
Dominar esta decisión arquitectónica es clave para desarrollar aplicaciones de escritorio modernas con IA.